Querying Data with AWS Glue and Amazon Athena
Contents
- Solution overview and simplified architecture diagram
- AWS CDK script (TypeScript)
- AWS Glue Crawler configuration
- Amazon Athena query examples
Solution Overview
This pipeline demonstrates how to create a serverless data analytics system using AWS Glue and Amazon Athena to query large datasets stored in Amazon S3. The system uses AWS Glue to catalog the data and Amazon Athena to run SQL queries directly against the data in S3, providing a scalable and cost-effective solution for data analysis.
By combining AWS Glue, Amazon Athena, and Amazon S3, developers can create a powerful, serverless solution for data analytics. This approach showcases the strength and flexibility of AWS services in building scalable, automated data query systems.
Use Case Description
In this scenario, large datasets are stored in an S3 bucket. AWS Glue is configured to crawl this data, infer its schema, and create a catalog of available datasets. Once the data is cataloged, Amazon Athena can be used to run SQL queries directly against the data in S3.
The AWS Glue Crawler automatically detects the schema of the data and updates the AWS Glue Data Catalog. This catalog serves as a persistent metadata store, making the data readily available for querying with Athena. Athena uses the information from the Data Catalog to know how to read the data from S3.
Users can then write SQL queries in Athena, which are executed directly against the data in S3 without the need to load the data into a separate database. Query results are stored in a designated S3 bucket for further analysis or visualization.
This automated analytics pipeline is designed to be scalable, capable of handling large volumes of data by leveraging the distributed query execution capabilities of Athena. It eliminates the need for infrastructure management, as both AWS Glue and Amazon Athena are fully managed services.
Industry Applications
This solution is applicable across various industries that deal with large-scale data analysis, including finance, healthcare, e-commerce, and manufacturing. Any application that involves querying large datasets for insights, reporting, or business intelligence can benefit from this pipeline. Examples include financial analytics, healthcare research data analysis, e-commerce customer behavior analysis, and manufacturing process optimization.
Simplified Architecture Diagram
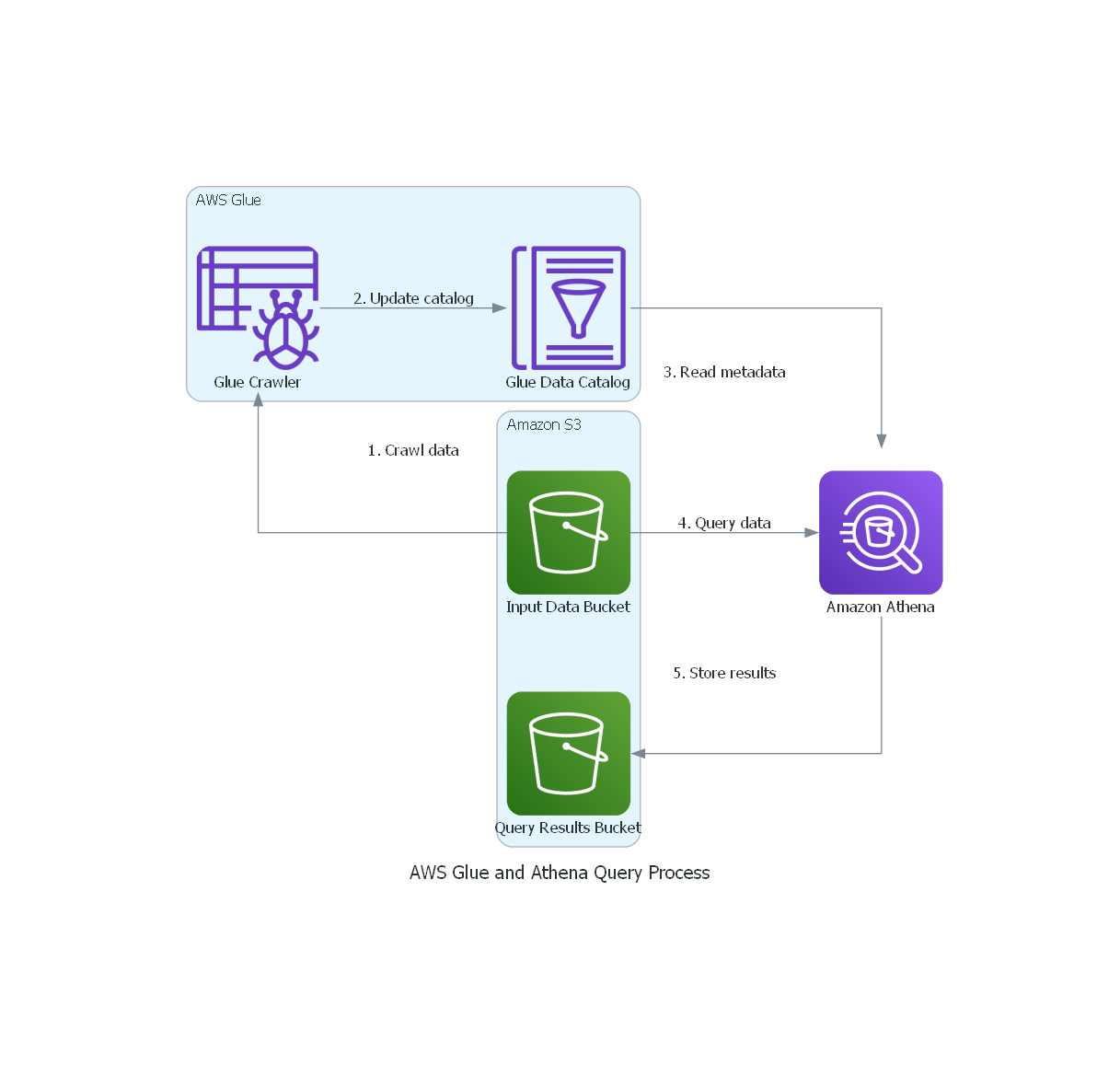
The architecture consists of:
- Amazon S3 Buckets: Store raw input data and query results.
- AWS Glue Data Catalog: Contains metadata about datasets.
- AWS Glue Crawler: Infers the schema of data in S3 and populates the Data Catalog.
- Amazon Athena: Executes SQL queries against data in S3.
- IAM Roles: Grant necessary permissions for AWS Glue and Athena to access S3 and other AWS services.
AWS CDK Script (TypeScript)
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as glue from 'aws-cdk-lib/aws-glue';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as athena from 'aws-cdk-lib/aws-athena';
export class AwsGlueAthenaQueryStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Create S3 buckets for input data and query results
const dataBucket = new s3.Bucket(this, 'DataBucket', {
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const queryResultsBucket = new s3.Bucket(this, 'QueryResultsBucket', {
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
// Create IAM role for Glue
const glueRole = new iam.Role(this, 'GlueRole', {
assumedBy: new iam.ServicePrincipal('glue.amazonaws.com'),
});
glueRole.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'));
dataBucket.grantRead(glueRole);
// Create Glue database
const glueDatabase = new glue.CfnDatabase(this, 'GlueDatabase', {
catalogId: this.account,
databaseInput: {
name: 'mydatabase',
},
});
// Create Glue Crawler
const glueCrawler = new glue.CfnCrawler(this, 'GlueCrawler', {
role: glueRole.roleArn,
targets: {
s3Targets: [{ path: dataBucket.bucketName }],
},
databaseName: glueDatabase.ref,
schedule: {
scheduleExpression: 'cron(0 1 * * ? *)',
},
});
// Create Athena workgroup
new athena.CfnWorkGroup(this, 'AthenaWorkGroup', {
name: 'MyAthenaWorkGroup',
recursiveDeleteOption: true,
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${queryResultsBucket.bucketName}/athena-results/`,
},
},
});
}
}
AWS Glue Crawler Configuration
The AWS Glue Crawler is configured in the CDK script above. It's set to run daily at 1:00 AM UTC, crawling the data in the S3 bucket and updating the Glue Data Catalog. You can adjust the schedule as needed for your use case.
Amazon Athena Query Examples
Once your data is cataloged by AWS Glue, you can start querying it using Amazon Athena. Here are some example queries:
- Basic SELECT query:
SELECT *
FROM mydatabase.mytable
LIMIT 10;
- Aggregation query:
SELECT category, COUNT(*) as count, AVG(price) as avg_price
FROM mydatabase.products
GROUP BY category
ORDER BY count DESC;
- JOIN query (assuming you have multiple tables):
SELECT o.order_id, o.order_date, c.customer_name, p.product_name
FROM mydatabase.orders o
JOIN mydatabase.customers c ON o.customer_id = c.customer_id
JOIN mydatabase.products p ON o.product_id = p.product_id
WHERE o.order_date >= DATE '2024-01-01';
- Using Athena's built-in functions:
SELECT
DATE_TRUNC('month', event_timestamp) AS month,
COUNT(*) AS event_count
FROM mydatabase.events
WHERE YEAR(event_timestamp) = 2024
GROUP BY DATE_TRUNC('month', event_timestamp)
ORDER BY month;
Remember to replace mydatabase and table names with your actual database and table names as defined in your AWS Glue Data Catalog.
This blog post provides a comprehensive guide to setting up a data analytics pipeline using AWS Glue and Amazon Athena for querying data stored in Amazon S3. It includes an overview of the solution, an architecture diagram, an AWS CDK script for setting up the infrastructure, and example Athena queries. This serverless approach allows for scalable and efficient data analysis without the need to manage underlying infrastructure.