ETL Pipeline
Content Covered
- Solution and simplified architecture diagram
- AWS CDK Script (TypeScript)
- AWS Glue ETL Job (PySpark)
Solution
This pipeline demonstrates how to create an ETL process using AWS Glue to extract data from Amazon S3, transform it, and load it into a target data store (which could be another S3 bucket, a data warehouse like Amazon Redshift, or a database). The system utilizes AWS Glue's serverless architecture to provide a scalable and managed ETL service.
By using AWS Glue in conjunction with Amazon S3, developers can create a robust, serverless solution for data processing and analytics. This approach showcases the power and flexibility of AWS services in building scalable, automated data pipelines.
Use Case Description
In this scenario, raw data is stored in an S3 bucket. AWS Glue is configured to crawl this data, inferring its schema and creating a catalog of the available datasets. An AWS Glue ETL job is then created to process this data.
The ETL job, written in PySpark, reads the data from S3, performs necessary transformations (such as data cleansing, format conversion, or aggregations), and then writes the processed data to a target location. This could be another S3 bucket, a data warehouse, or a database, depending on the specific requirements.
This automated ETL pipeline is designed to be scalable, capable of processing large volumes of data by leveraging the distributed computing capabilities of Apache Spark, which AWS Glue uses under the hood. It eliminates the need for managing infrastructure, as AWS Glue is a fully managed service.
Industry domains
This solution is applicable across various industries that deal with large-scale data processing, including finance, healthcare, retail, and manufacturing. Any application that involves extracting data from various sources, transforming it for analysis, and loading it into a data store for querying can benefit from this pipeline. Examples include business intelligence systems, customer analytics platforms, and IoT data processing systems.
Simplified architecture diagram
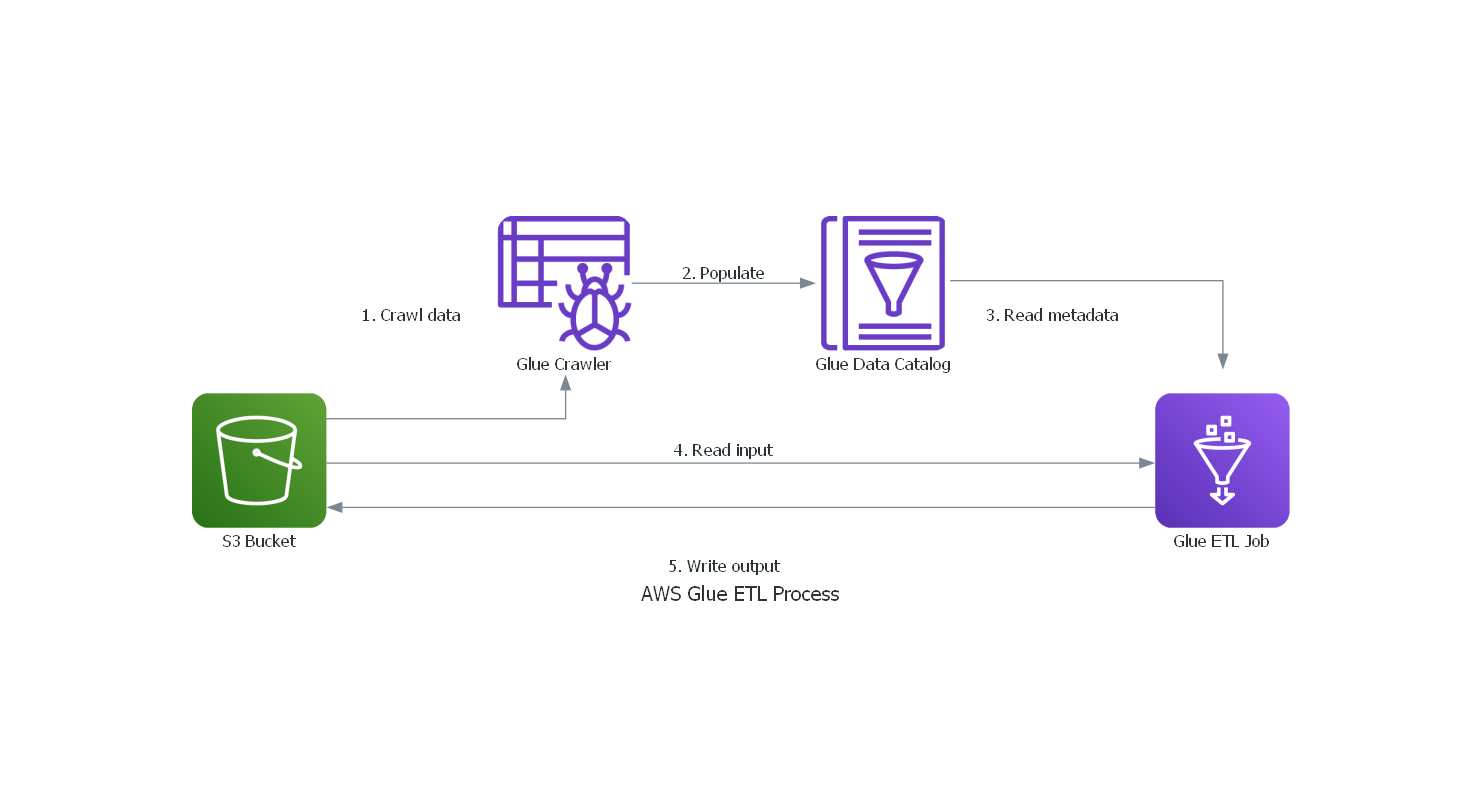
The architecture consists of:
- Amazon S3 Bucket: Stores the raw input data and processed output data.
- AWS Glue Data Catalog: Contains metadata about the datasets.
- AWS Glue Crawler: Infers the schema of the data in S3 and populates the Data Catalog.
- AWS Glue ETL Job: Processes the data using PySpark.
- IAM Role: Grants necessary permissions to AWS Glue to access S3 and other AWS services.
AWS CDK Script (TypeScript)
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as glue from 'aws-cdk-lib/aws-glue';
import * as iam from 'aws-cdk-lib/aws-iam';
export class AwsGlueS3EtlStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Create S3 buckets for input and output data
const inputBucket = new s3.Bucket(this, 'InputBucket', {
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
const outputBucket = new s3.Bucket(this, 'OutputBucket', {
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
// Create IAM role for Glue
const glueRole = new iam.Role(this, 'GlueETLRole', {
assumedBy: new iam.ServicePrincipal('glue.amazonaws.com'),
});
glueRole.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'));
inputBucket.grantRead(glueRole);
outputBucket.grantReadWrite(glueRole);
// Create Glue Database
const glueDatabase = new glue.CfnDatabase(this, 'GlueDatabase', {
catalogId: this.account,
databaseInput: {
name: 'mydatabase',
},
});
// Create Glue Crawler
const glueCrawler = new glue.CfnCrawler(this, 'GlueCrawler', {
role: glueRole.roleArn,
targets: {
s3Targets: [{ path: inputBucket.bucketName }],
},
databaseName: glueDatabase.ref,
schedule: {
scheduleExpression: 'cron(0 1 * * ? *)',
},
});
// Create Glue Job
const glueJob = new glue.CfnJob(this, 'GlueETLJob', {
command: {
name: 'glueetl',
pythonVersion: '3',
scriptLocation: 's3://' + inputBucket.bucketName + '/etl_script.py',
},
role: glueRole.roleArn,
defaultArguments: {
'--job-language': 'python',
'--job-bookmark-option': 'job-bookmark-enable',
},
executionProperty: {
maxConcurrentRuns: 2,
},
maxRetries: 0,
name: 'my-etl-job',
glueVersion: '3.0',
});
}
}
AWS Glue ETL Job (PySpark)
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Read data from S3
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "mydatabase", table_name = "input_data", transformation_ctx = "datasource0")
# Perform transformations
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("column1", "string", "column1", "string"), ("column2", "long", "column2", "long")], transformation_ctx = "applymapping1")
# Write transformed data back to S3
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://output-bucket/processed_data"}, format = "parquet", transformation_ctx = "datasink2")
job.commit()
This blog post provides a comprehensive guide to setting up an ETL pipeline using AWS Glue to process data stored in Amazon S3. It includes a solution overview, architecture diagram, AWS CDK script for infrastructure setup, and a sample AWS Glue ETL job written in PySpark. This serverless approach allows for scalable and efficient data processing without the need to manage underlying infrastructure.